RAGFlow × 企业知识库:从「PPT里吃灰」到「AI随叫随到」的落地指南
大多数企业知识库的现状:散落在 Confluence、SharePoint、飞书文档和本地硬盘里,员工找一份三年前的方案比写一份新方案还累。RAGFlow 就是来解决这个问题的——它不只是又一个「上传 PDF 然后问问题」的工具,而是一套能真正在金融、法务、制造、教育等行业落地的企业级 RAG 引擎。
一、企业知识库的三大死穴
在讲 RAGFlow 怎么做之前,先看企业知识库为什么总做不起来:
死穴典型表现根因
文档太杂PDF、Word、PPT、Excel、扫描件、网页、飞书文档——格式五花八门传统系统只处理纯文本,复杂格式直接「消化不良」
切不准把表格切成碎片、把多页合同切成互不关联的片段一刀切的固定长度切片,语义断裂
幻觉收不住AI 回答看似流畅,但关键数据对不上号,没人敢用召回不准 + 没有可追溯的引用来源
这三个问题不解决,企业知识库永远是「演示一次,再没人用」。
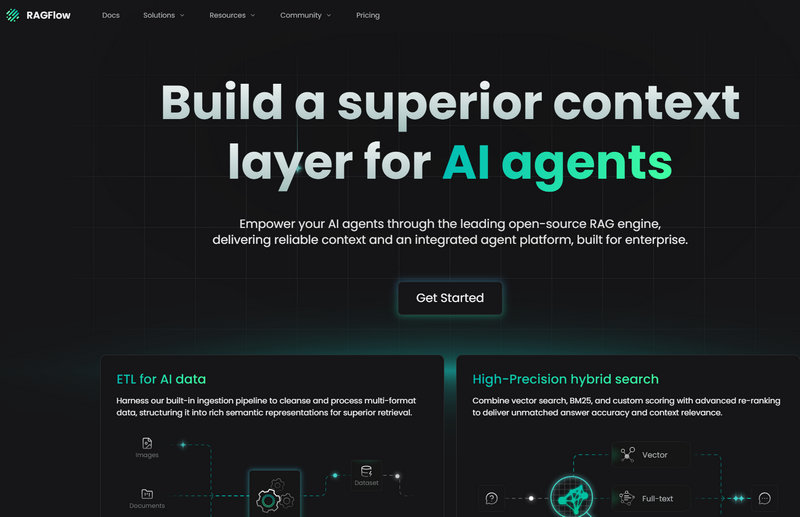
RAGFlow官网首页
二、RAGFlow 是什么
RAGFlow 是 InfiniFlow 团队开源的 RAG(检索增强生成)引擎,背后有 GitHub 数万 Star 的社区验证。
一句话定义:
RAGFlow 是一套融合了深度文档理解、智能切片、Agent 能力的开源 RAG 引擎,帮企业把散落的文档变成 AI 可理解、可检索、可引用的「上下文层」。
它的定位非常清晰——为 AI Agent 构建高质量上下文。官网首页的标语就是 "Build a superior context layer for AI agents"。
- 官网:https://ragflow.io
- GitHub:https://github.com/infiniflow/ragflow
- 协议:Apache 2.0(开源,可商用)
- 云服务:https://cloud.ragflow.io
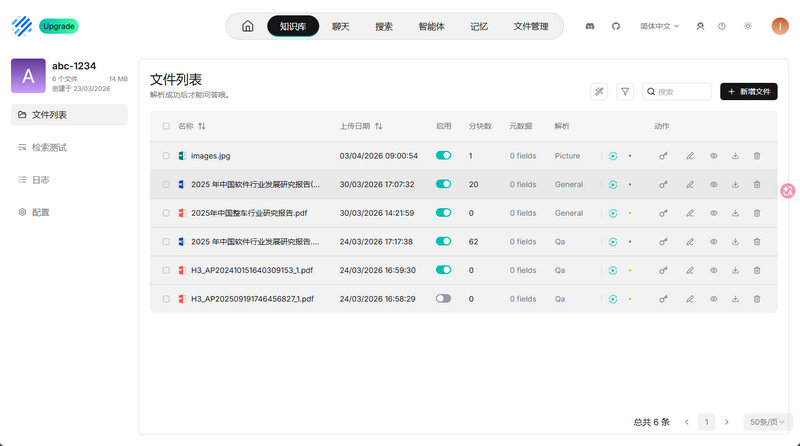
RAGFlow知识库界面
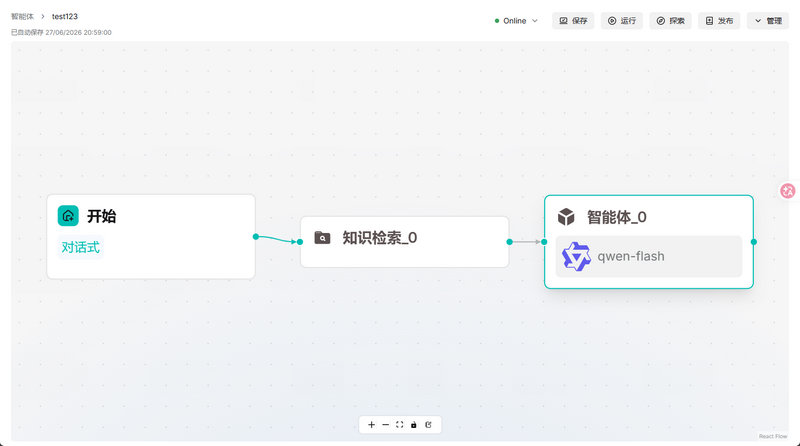
RAGFlow智能体界面
三、RAGFlow 怎么逐个击破企业知识库的死穴
3.1 文档太杂 → 深度文档理解 + 异构数据引擎
RAGFlow 内置了完整的 ETL 管道,针对企业常见文档格式做了深度优化:
文件类型RAGFlow 的处理能力
PDF解析文字、表格、图片,支持扫描件 OCR
Word / PPT / Excel保留结构语义,表格不拆碎
图片 / 扫描件多模态模型提取图片描述和其中文字
网页URL 直接抓取解析
飞书 / Confluence / Notion原生数据同步连接器,增量拉取
Discord / Google Drive / S3同样支持原生同步
关键在于「保留结构」。比如一份 PDF 里的表格,RAGFlow 不会把它拆成碎片文本,而是保留行列关系——这在财务报告、技术规格书这类文档中是致命的差异。
3.2 切片不准 → 模板化智能切片
RAGFlow 不是简单按 500 字一切。它提供了模板化的切片方案:
- 多种切片模板:针对不同文档类型(合同、手册、论文、Q&A)预设切片策略
- 可视化 + 可干预:切片过程完全透明,你可以看到每一块的边界,手动调整不合理的地方
- 稳定可解释:切片逻辑可复盘,不至于「改了模型版本,切片全变了」
这种设计在企业场景尤其重要——法务合规部门需要知道「AI 到底读了哪一段」,而不是信任一个黑盒。
3.3 幻觉收不住 → 多路召回 + 融合重排序 + 可追溯引用
RAGFlow 的检索链采用了「多路召回 + 融合重排序」策略:
用户提问 → 关键词召回 + 语义召回(多路) → 融合排序 → 精选上下文 → LLM 生成 + 标注引用
关键特性:
- 可追溯引用:每个回答都附带来源快照,点击即可跳转到原始文档的对应位置
- 人工校验入口:切片过程可视化,支持手动修正
- 企业级 answer:不是为了「听起来像人话」而是「确保每个论断都能在知识库里找到依据」
四、不只是「问答机器人」:RAGFlow 的 Agent 能力
企业知识库真正落地的标志是:不光是「员工来问」,还能自动完成工作任务。
RAGFlow 在 Agent 层面提供了:
能力场景
Agentic Workflow多步骤自动化——比如「查一下 Q3 出货量 → 和去年对比 → 生成邮件摘要发给我」
MCP 支持模型上下文协议,与其他 MCP 兼容的工具 / 服务互通
代码执行器Agent 可执行 Python/JS 代码,做数据计算和复杂逻辑处理
记忆功能Agent 记住上下文和用户偏好,不用每次从头对话
多渠道接入飞书、Discord、Telegram、Line 等聊天渠道直接对接到知识库
这意味着企业可以把 RAGFlow 接进飞书群,员工 @ 一下 AI 就能查产品手册、技术规范、历史工单——不需要打开任何新系统。
五、企业级就绪:安全、合规、可控
光功能强不够,企业还要考虑能不能「放心用」。
企业关切RAGFlow 的答案
数据不出境私有化部署,数据完全在自有服务器上
权限与治理知识库权限管理,不同团队/部门访问不同数据集
多模型不锁定支持 OpenAI、DeepSeek、Gemini 等主流模型,API Key 你自己配
可观测性内置调用监控与日志,每次查询耗时、召回结果、token 消耗都可见
模型版本可控LLM 和 Embedding 模型均可独立配置和切换,不受供应商锁定
合规审计引用可追溯,回答可回溯
对于金融、法务、医疗等强监管行业,私有化部署 + 可追溯引用 + 多模型不锁定是刚需。
六、行业落地场景
RAGFlow 官网已经公开了四个重点行业方案:
金融服务
- 合规文档智能检索:合同条款、监管文件一键查
- 投研报告辅助:海量研报 + 公告解析,分析师快速获取上下文
- 客服知识库:产品手册、费率说明、业务流程 AI 即时答复
法律与合规
- 法律法规库:法条、司法解释、判例全文检索 + 引用溯源
- 合同审查辅助:历史合同条款对比,风险条款自动标记
- 合规培训:从企业制度文档自动生成培训问答
制造业
- 技术文档库:设备手册、工艺文件、SOP 全量向量化,产线工人语音查询
- 工单知识沉淀:历史故障处理方案自动入库,新问题匹配旧经验
- 供应商管理:多格式供应商文件统一检索
教育
- 课程知识库:教材、课件、论文结构化,学生自然语言提问
- 科研文献助手:大规模论文索引 + 摘要生成
- 校务问答:学籍制度、办事流程 AI 自助答复
七、落地路径:三步让企业知识库跑起来
基于 RAGFlow 的实际部署经验,推荐三阶段推进法:
第一阶段:试点见效(1-2 周)
选一个部门 + 一个高频场景 → 整理 50-100 份核心文档 → RAGFlow 私有化部署 → 导入文档 → 验证问答质量
建议新手从 客服知识库 或 技术文档问答 切入,文档格式相对规整,容易快速见效。
第二阶段:规模铺开(1-2 月)
接入 Confluence / 飞书等数据源 → 配置增量同步 → 按部门建数据集 + 权限 → 接入聊天渠道 → 收集反馈调优切片策略
此阶段重点是从「手动导入」切换到「自动同步」,让知识库保持新鲜度。
第三阶段:深度整合(持续)
引入 Agent 工作流 → 对接内部系统 API → MCP 互联 → 从「问答」升级到「自动执行」
到了这一步,知识库不再是「员工的搜索引擎」,而是自动化工作流的一环。
八、与同类方案的对比
维度RAGFlowLangChain 生态自建闭源 SaaS(如 Glean)
部署方式私有化 / 云服务完全自建SaaS 云端
文档理解深度内置深度解析引擎需自行集成多种解析器好,但无法自控
切片策略模板化 + 可视化 + 可干预需手写逻辑黑盒
Agent 能力内置 agentic workflow + MCP框架提供,需大量开发受限
数据安全完全自主可控完全自主可控数据在供应商服务器
多模型支持✅ 不锁定✅ 自由通常锁定
上手速度Docker 一条命令需要较强工程能力快但贵
渠道接入飞书/ Discord/ Telegram/ Line需自建部分支持
费用免费开源人力 + 算力按席收费,贵
总结
RAGFlow 对企业知识库落地最大的贡献,是把「AI 能读懂企业文档」这件事做到了一线可用。
- 深度理解:表格不拆碎、扫描件能 OCR、图片有多模态描述
- 可干预切片:透明、可调整、可审计,不是黑盒
- 可追溯回答:每个答案有出处,法务合规也敢用
- 不只是问答:Agent 工作流 + MCP + 代码执行器,知识库融入自动化
- 企业就绪:私有化部署、多模型不锁定、数据完全自控
如果你的企业正在或即将考虑「把知识库接入 AI」,先用 RAGFlow 私有化部署跑通一个试点场景,比什么调研报告都强。
官网:https://ragflow.io☁️ 免费云服务试用:https://cloud.ragflow.io GitHub:https://github.com/infiniflow/ragflow — Apache 2.0 开源
以上是 RAGFlow × 企业知识库:从「PPT里吃灰」到「AI随叫随到」的落地指南 的全部内容, 来源链接: yudiai.com/geo/10026.html